Hadoop产生的背景
1. HADOOP最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
2. 2003年开始谷歌陆续发表的三篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
——BigTable 数据库:OLTP 联机事务处理 Online Transaction Processing 增删改
OLAP 联机分析处理 Online Analysis Processing 查询 真正的作用:提供了一种可以在超大数据集中进行实时CRUD操作的功能3.Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
Hadoop是啥
Hadoop的官网:
1、Hadoop是Apache旗下的一套开源软件平台
2、Hadoop提供的功能:利用服务器集群,根据户自定义业逻辑对海量数进行分布式处理
3、Hadoop的核心组件:
1)Hadoop Common:支持其他Hadoop模块的常用工具。
2) Hadoop分布式文件系统(HDFS™):一种分布式文件系统,可提供对应用程序数据的高吞吐量访问。
3) Hadoop YARN:作业调度和集群资源管理的框架。
4) Hadoop MapReduce:一种用于并行处理大型数据集的基于YARN的系统。
大数据的处理主要就是存储和计算。
如果说安装hadoop集群,其实就是安装了两个东西: 一个操作系统YARN 和 一个文件系统HDFS。其实MapReduce就是运行在YARN之上的应用。
操作系统 文件系统 应用程序
win7 NTFS QQ,WeChat YARN HDFS MapReduce4、hadoop的概念:
狭义上: 就是apache的一个顶级项目:apahce hadoop
广义上: 就是指以hadoop为核心的整个大数据处理体系
5、Apache的其他Hadoop相关项目包括:
- :一种用于供应,管理和监控Apache Hadoop集群的基于Web的工具,其中包括对Hadoop HDFS,Hadoop MapReduce,Hive,HCatalog,HBase,ZooKeeper,Oozie,Pig和Sqoop的支持。Ambari还提供了一个用于查看群集运行状况的仪表板,例如热图和可以直观地查看MapReduce,Pig和Hive应用程序的功能,以及以用户友好的方式诊断其性能特征的功能。
- :数据序列化系统。
- :无单点故障的可扩展多主数据库。
- :管理大型分布式系统的数据收集系统。
- :可扩展的分布式数据库,支持大型表格的结构化数据存储。
- :提供数据汇总和即席查询的数据仓库基础架构。
- :可扩展的机器学习和数据挖掘库。
- :用于并行计算的高级数据流语言和执行框架。
- :用于Hadoop数据的快速和通用计算引擎。Spark提供了一个简单而富有表现力的编程模型,它支持广泛的应用程序,包括ETL,机器学习,流处理和图计算。
- :一种基于Hadoop YARN的通用数据流编程框架,它提供了一个强大且灵活的引擎,可执行任意DAG任务来处理批处理和交互式用例的数据。Hado™,Pig™和Hadoop生态系统中的其他框架以及其他商业软件(例如ETL工具)正在采用Tez来替代Hadoop™MapReduce作为底层执行引擎。
- :分布式应用程序的高性能协调服务。
HADOOP在大数据、云计算中的位置和关系
1、云计算是分布式计算、并行计算、网格计算、多核计算、网络存储、虚拟化、负载均衡等传统计算机技术和互联网技术融合发展的产物。借助IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)等业务模式,把强大的计算能力提供给终端用户。1、
2、现阶段,云计算的两大底层支撑技术为“虚拟化”和“大数据技术”
3、 而HADOOP则是云计算的PaaS层的解决方案之一,并不等同于PaaS,更不等同于云计算本身。
Hadoop的技术应用
HADOOP应用于数据服务基础平台建设
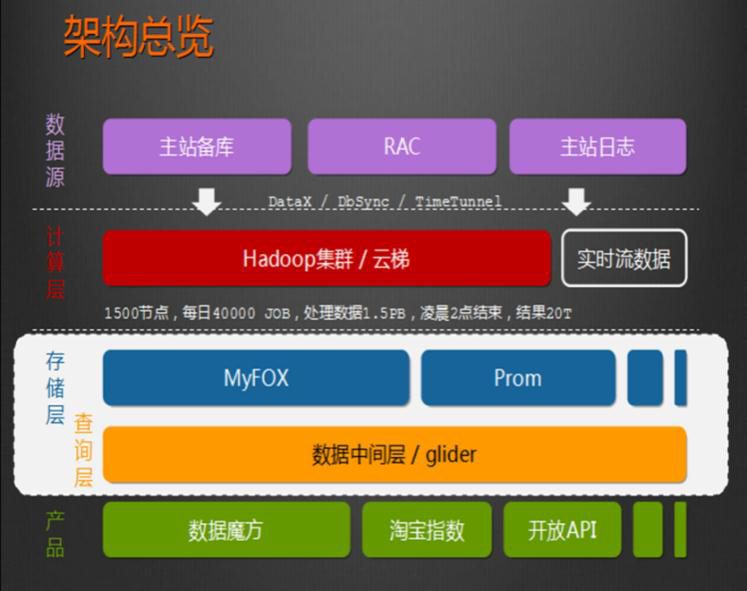
HADOOP用于用户画像
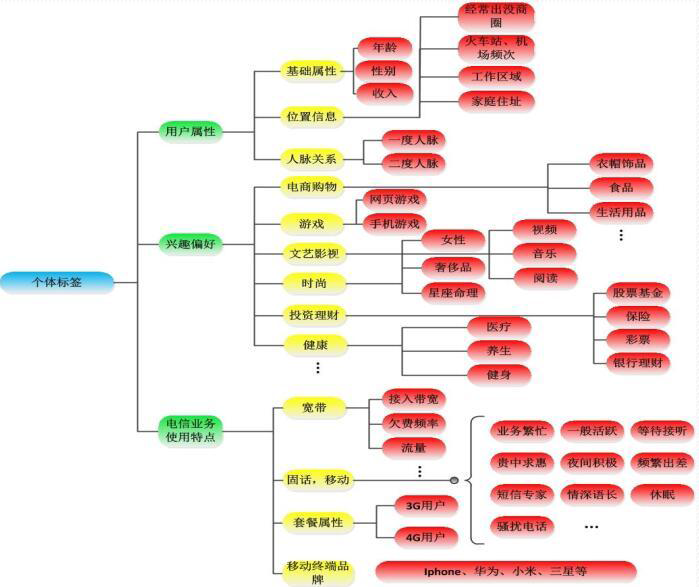
该图是中国电信的用户画像标签体系。
HADOOP用于网站点击流日志数据挖掘
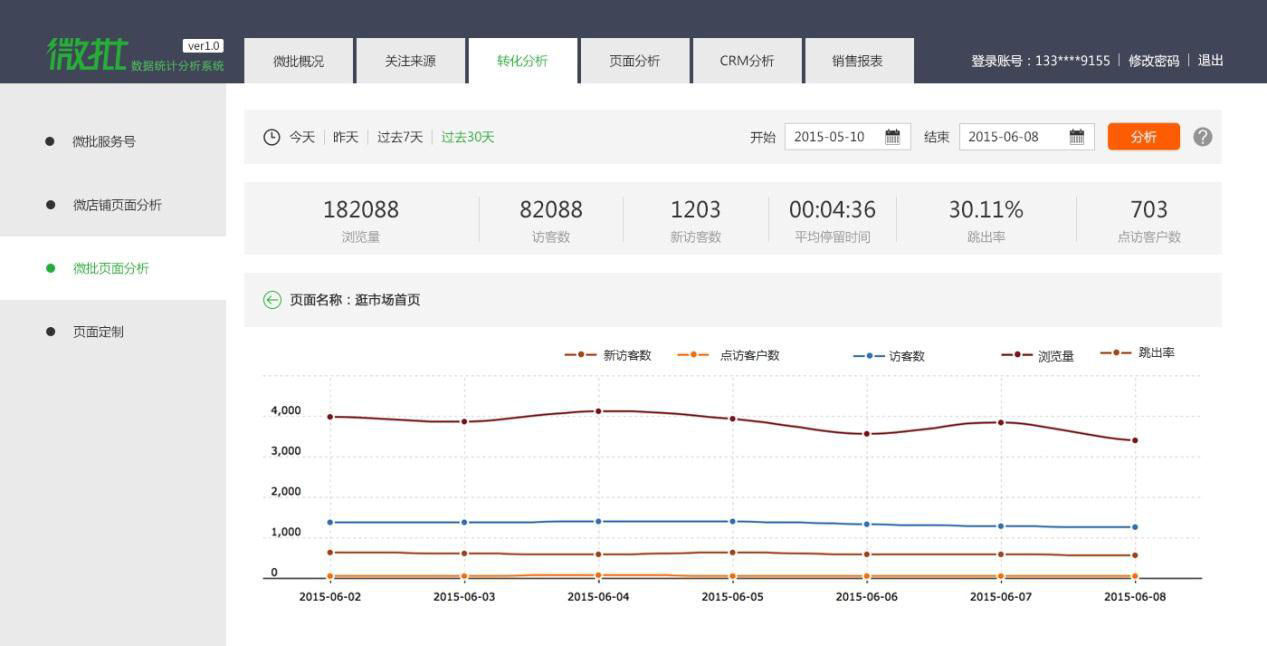
总结:hadoop并不会跟某个具体的行业或者某个具体的业务挂钩,它只是一种用来做海量数据分析处理的工具。
HADOOP生态圈以及各组成部分的简介
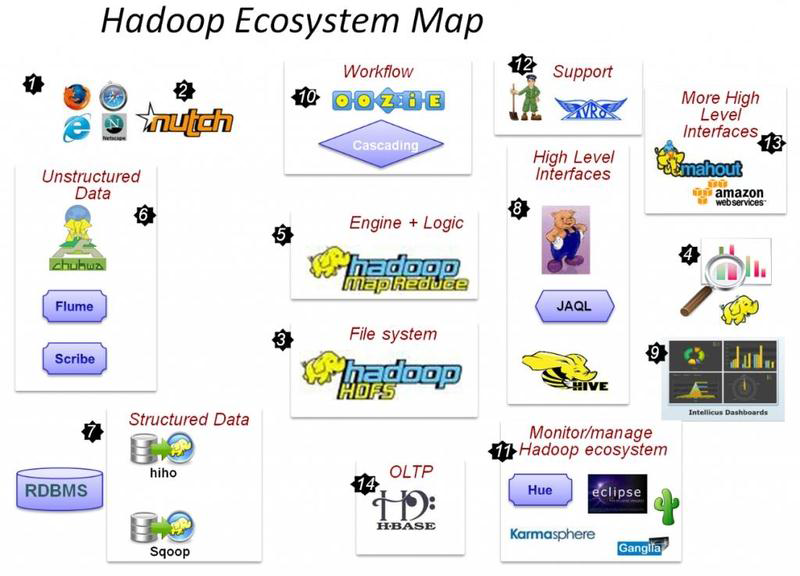
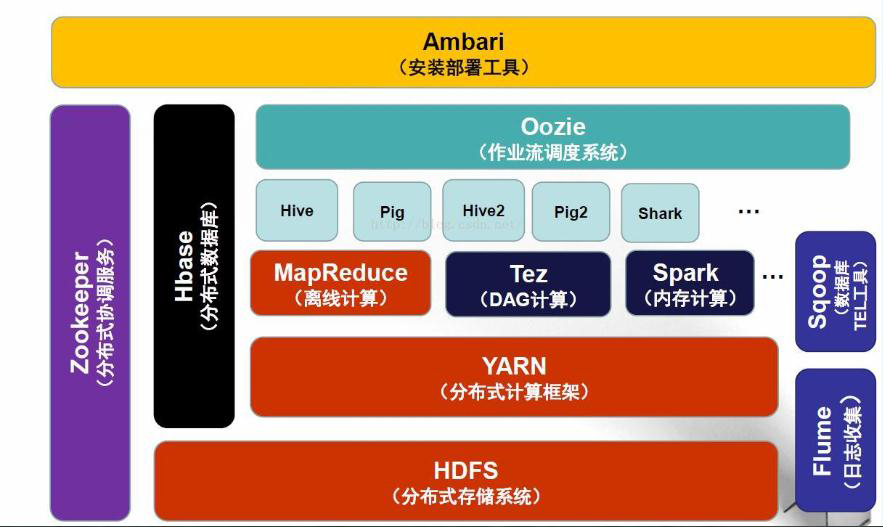
重点组件:
HDFS:Hadoop的分布式文件存储系统。
MapReduce:Hadoop的分布式程序运算框架,也可以叫做一种编程模型。
Hive:基于Hadoop的类SQL数据仓库工具
Hbase:基于Hadoop的列式分布式NoSQL数据库
ZooKeeper:分布式协调服务组件
Mahout:基于MapReduce/Flink/Spark等分布式运算框架的机器学习算法库
Oozie/Azkaban:工作流调度引擎
Sqoop:数据迁入迁出工具
Flume:日志采集工具
获取数据的三种方式
1、自己公司收集的数据--日志 或者 数据库中的数据
2、有一些数据可以通过爬虫从网络中进行爬取
3、从第三方机构购买
国内HADOOP的就业情况分析
1、HADOOP就业整体情况
A. 大数据产业已纳入国家十三五规划
B. 各大城市都在进行智慧城市项目建设,而智慧城市的根基就是大数据综合平台
C. 互联网时代数据的种类,增长都呈现爆发式增长,各行业对数据的价值日益重视
D. 相对于传统JAVAEE技术领域来说,大数据领域的人才相对稀缺
E. 随着现代社会的发展,数据处理和数据挖掘的重要性只会增不会减,因此,大数据技术是一个尚在蓬勃发展且具有长远前景的领域
2、 HADOOP就业职位要求
大数据是个复合专业,包括应用开发、软件平台、算法、数据挖掘等,因此,大数据技术领域的就业选择是多样的,但就HADOOP而言,通常都需要具备以下技能或知识:
硬实力
A. HADOOP分布式集群的平台搭建
B. HADOOP分布式文件系统HDFS的原理理解及使用
C. HADOOP分布式运算框架MAPREDUCE的原理理解及编程
D. Hive数据仓库工具的熟练应用
E. Flume、sqoop、oozie等辅助工具的熟练使用
F. Shell/python等脚本语言的开发能力
软实力
A. 解决问题的能力(调试,阅读文档)
B. 沟通协调能力(寻求帮助)
C. 学习提升自己的能力(自我提高)
D. 组织管控能力(管理能力)